
作战规划中的人工智能:深入探讨如何将 AlphaGo 等人工智能融入军事规划从而彻底改变战略决策
原标题:作战规划中的人工智能:深入探讨如何将 AlphaGo 等人工智能融入军事规划,从而彻底改变战略决策
人工智能的能力越来越强,其深远影响也慢慢变得明显。像 ChatGPT 这样的程序正在重塑人类活动的许多领域,其速度之快令各机构难以跟上。
军方已经注意到人工智能(AI)的潜力。公开资料显示,美国、俄罗斯等国军队都在开发包含人工智能的规划过程。这些军事规划过程的细节并未公开,但这并不妨碍将澳大利亚国防军的规划过程与现有的人工智能规划过程作比较。这样做可以推断出联合军事评估过程(JMAP)如何通过整合人工智能进行改进。
澳大利亚能够最终靠整合人工智能来改进 JMAP。本文探讨了这种整合是否可行,并得出结论认为是可行的。文章将 JMAP 与计算机程序 AlphaGo 中固有的规划过程进行了比较,从道德、理论和实践的角度分析了人工智能增强型 JMAP 对澳大利亚国防军(ADF)的适用性。本文了选择 AlphaGo(一个玩棋盘游戏围棋的程序)作为比较规划程序有几个原因。AlphaGo 代表了人工智能的最新应用。和AI的军事应用不同,AlphaGo 的信息绝大多数都是公开的。最后,AlphaGo 之所以出名(至少在人工智能界),是因为它在规划方面可能展现出了真正的创造力。比较研究了 JMAP 和 AlphaGo 如何执行两项基本的规划功能:设定作战环境和开发和评估可能的解决方案。结论是,通过将AI更好地融入规划,JMAP 可以更适用于 ADF。
人们对利用技术增强军事规划和决策的兴趣并不新鲜。在计算机化的长期趋势中,人工智能增强规划是顺理成章的下一步。1963 年,美国空军委托编写了一份关于增强人类智力方法的报告。恩格尔巴特(Engelbart)将增强人类智力定义为 提高人类处理复杂问题的能力,以获得适合其特定需求的理解力,并推导出处理问题的方案。它特别指出,计算机是实现这一目标的有力工具。AI是这方面的最新发展。如今,澳大利亚国防军的条令精确指出:澳大利亚国防军一定要通过更多地用AI来提高人民的战斗力。虽然人工智能的定义比比皆是,但国防军将AI定义为 机器表现出看似智能行为的一大类技术。
AlphaGo 就是这种人工智能的一个例子,它试图在中国古代战略棋盘游戏围棋中获胜。为了有效地做到这一点,AlphaGo 一定要了解环境并制定行动方案。将 AlphaGo 怎么样才能做到这一点与 JMAP 如何寻求解决军事问题作比较,为比较和随后的分析提供了依据。
JMAP 有一套独特的理解环境的方法。JMAP 的第一步是确定范围和框架,详细描述观察到的系统和期望的系统。我们采用了很多方法,包括创建图表,以捕捉系统内的参与者、关系、功能和紧张关系。这种图表就是系统模型。任何模型的保真度都是有限的。例如,可视化表示法仅限于三维空间,其他维度的特征最多只可以通过颜色等其他线索来表示。面对这些限制,目标是建立一个能充分代表复杂系统的模型,为规划者提供信息。为了适应这种限制,确定范围和框架在大多数情况下要将结构混乱和/或定义不清的情况解构为结构化和可理解的问题集。一个臭名昭著的例子就是北约的 PowerPoint 幻灯片,该幻灯片试图用图形说明阿富汗冲突的参与者和动态(图 1)。
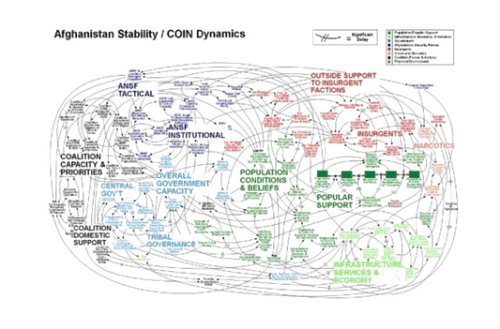
图 1--阿富汗环境的图形模型,说明描绘复杂系统或结构混乱情况所面临的挑战。
作战环境联合情报准备(JIPOE)构成了作战环境的定义......和对环境影响的描述,是对范围界定和框架制定的补充。这种描述为范围界定中开发的模型规则提供了信息。
与 JMAP 一样,AlphaGo 也开发了一个环境模型,在围棋游戏中,环境由棋盘上的棋子位置定义。它使用的方法类似于图像分类和面部识别软件。棋盘(包括所有棋子的状态)被当作一幅 19 x 19 的图像,神经网络中的各层构建出棋盘状态的抽象表示。这样一来,AlphaGo 就实际做到了 框定环境。用模型表示环境的当前状态只是理解环境的一部分。然后,AlphaGo 使用价值网络来评估给定的棋盘位置,以及每步棋可能会产生的棋盘位置。它对每个局面的评估都采用一个简单的指标:从该局面获胜的概率。尽管可能过于简单,但这种方法的重点全部符合战争的第一原则:选择并保持目标。
JMAP 和人工智能所采用的了解作战环境的方法有相似之处。两者都试图创建一个现实模型。在 JMAP 中,这一模型是在计划人员的生物大脑中实例化的,并辅以各种认知人工制品,如图表、地图和书面文本。人工智能中也有一个模型,但它是通过 AlphaGo 的多层神经网络进行数字编码的。每个模型都将环境视为由节点和链接组成的系统。从根本上说,JMAP 和人工智能描述环境的方式并没什么不协调之处。然而,仅仅因为它们使用了相似的方法,并不代表 JMAP 和AI会给出相似的结果,因为自主系统可能拥有与人类队友不同的传感器和数据源,它可能在不同的操作环境假设下运行。当利用对环境的了解来制定和评估行动方案时,这些好处就会显现出来。
JMAP 行动方案的制定和评估是参谋人员和指挥官之间对话的结果。行动方案的核心思想往往是指挥官的想法,是经验、判断和直觉的综合体现。由于这些过程发生在指挥官的头脑中,因此有些不透明。不过,行动方案的制定过程中也有外部可见的因素可以分析。兵棋推演就是 JMAP 中新创意的一个可能来源。美国核战略学家谢林(Schelling)在对核武器控制文献的贡献中,论证了游戏在引入规划者无法以其他方式获得的新想法方面的价值。他指出:一个人无论分析多么严谨,想象力多么丰富,都不可能做到的一件事,就是列出一份他永远都不可能想到的事情清单!。兵棋推演也可拿来评估行动方案,这与 AlphaGo 使用蒙特卡洛模拟来做评估的方法类似。
AlphaGo 会反复考虑行动方案,每走一步棋后都会重新评估,以选择最大有可能取得胜利的下一步合法棋步。它是通过策略网络来做到这一点的。它建立在价值网络的基础上:策略网络将棋盘位置 s 的表示作为输入,通过许多具有参数 σ(SL [监督学习] 策略网络)或 ρ(RL [强化学习] 策略网络)的卷积层,并输出合法棋步 a 的概率分布 pσ(as) 或 pρ(as),由棋盘上的概率图表示。由于其开发和比较计划的方式,AlphaGo 开发出了新颖的开局棋步,包括一些人类根本没办法理解的棋步。用于制定行动方案的AI在这方面能表现出真正的创造力,这一点在 2016 年得到了证明。在战胜韩国围棋冠军李世石的比赛中,AlphaGo 下了一步出人意料的棋(被广泛称为第 37 手)。这步棋将一颗棋子深入塞多尔的棋盘区域,打破了传统的围棋智慧,令观察者大惑不解。这步棋震撼了Sedol,以至于他短暂地离开了房间。这步棋改变了棋局的走向,对 AlphaGo 有利,AlphaGo 的聪明才智显露无遗。Sedol 最终被自己和大多数人类几乎无法想象的创造性棋步击败。这让我们正真看到了人工智能如何增强规划能力。
AlphaGo 的行动方案开发和评估在很多方面都与 JMAP 相似。它不是对所有可能的行动进行 蛮力 评估,而是对不同选项进行知情的开发和评估。其结果是,AlphaGo 评估的局面比深蓝在与卡斯帕罗夫的国际象棋比赛中所做的少数千倍;利用策略网络更智能地选择这些局面,并使用价值网络更精确地评估这些局面来进行补偿--这种方法或许更接近人类的下棋方式。同样,兵棋推演并不考虑无穷无尽的行动方案,而是只考虑指挥官选定的行动方案,或许只关注这些行动方案的选定方面。与 JMAP 的相似之处促进了人工智能的整合。
AlphaGo 和 JMAP 都利用过去的例子来训练未来。AlphaGo 的开发者详细的介绍了训练不同版本软件所采用的很多方法,这一些方法要么依赖于人类过去的围棋比赛输入,要么依赖于模拟围棋对手的自我对弈。用人类下过的棋谱训练算法类似于研究过去的战役:这是职业军事教育的支柱。有趣的是,这种方法似乎也存在隐患,因为 从由完整棋局组成的数据中预测对局结果的天真方法会导致过度拟合。换句话说:AlphaGo 可能会掉入许多军队都熟悉的陷阱,即为了赢得最后一场战争而进行训练。我们应该共同努力训练人工智能,使其做出的决策能适应未来的一般对局/冲突。
总的来说,AlphaGo 理解环境、制定和评估行动方案的方式与 JMAP 相似,但又有足够的不同,因此可能会带来优势。目前形式的 JMAP 未能充分的利用人类和人工智能的不同优势来解决军事问题。
接下来,将分析AI在澳大利亚国防军规划中的适用性,以了解是不是可以利用这些优势。AI在国防军规划中的适用性需要从伦理、理论和实践的角度来考虑。
对军事规划中的人工智能进行任何分析,都一定要考虑适用于国防军的道德问题。关于AI在军事决策中的应用,有相当多的伦理争论。允许人工智能或自主系统使用致命武力或做出导致使用致命武力的决策尤其具有争议性。斯帕罗得出结论认为,使用致命武力必须始终由人类直接负责,因此人工智能不能指挥致命武力。辛普森和穆勒对辩论进行了调查,得出结论认为,指挥官仍可对AI做出的决定负责,因此仍允许用AI。将人类纳入人工智能增强型 JMAP 进一步减轻了和AI无监督军事决策相关的许多担忧。
使用人工智能生成行动方案为人类控制和监督留下了很大的空间。AlphaGo 使用的蒙特卡洛办法能够在人类的指导下制定出更符合指挥官意愿的计划,或考虑到人类规划者的道德考量。在 1999 年的研究中,迈尔斯和李使用了超越单纯随机化的技术,通过AI生成不同质量的计划。他们的方法 植根于偏差的创建,偏差会使计划人员专注于具有特定属性的解决方案,这样 用户就能够最终靠指定元理论中应用于偏差生成的方面,选择性地引导计划人员进入计划空间的理想区域。这为人类监督致命计划和决策的制定提供了一种可能的形式。(请注意,上文使用的 偏见 一词没有一点负面含义,仅指人类以特定方式指导人工智能的能力)。
关于致命自主武器系统(LAWS)合法性的有关问题,联合国正在进行辩论,特别是《禁止或限制使用某些可被认为具有过分伤害力或滥杀滥伤作用的常规武器公约》(简称《特定常规武器公约》)。澳大利亚在2020年提交给《特定常规武器公约》的文件中总体上对自主系统持支持态度,称 澳大利亚认识到人工智能为军事和民用技术带来的潜在价值和益处。澳大利亚主张对AI系统的人类控制进行广泛定义。呈件的结论是,适用现有的国际人道主义法足以解决对AI系统的关切,为人工智能增强型联合军事行动计划敞开大门,但须经过现有的审查程序。因此,澳大利亚似乎不反对将人工智能增强规划适用于国防军。
为了分析它们对澳大利亚国防军的适用性,考虑了军事组织如何应用 JMAP 和人工智能增强型规划的理论方面。这就需要了解这样一个澳大利亚国防军组织在进行规划时是如何行动、认知和决策的。这首先是一个社会学问题。基于对军事组织的社会学理解,认知科学为理解人类认知与非人类要素的融合提供了一个理论框架。
吉登斯认为,现代社会在很大程度上是由专家系统构成的,而专家系统是一类可以涵盖军事总部的实体。专家系统有许多特性,但它们与认知的关系对当前的问题最为重要。克诺尔-塞蒂娜研究了专家系统在科学中的行为,展示了某些活动的开展是如何塑造和改变一个组织的。她指出,高能粒子实验室在进行实验时,创造了一种分布式认知,这种认知也是一种管理机制:通过这种话语,工作变得协调,自组织成为可能。虽然她的研究重点是作为知识组织的科学实验室,但她也承认,科学以外的专家文化 也可以使用认识论文化这一概念。从事规划工作的总部可以表现出分布式认知,对 分布式认知 概念的进一步探讨有助于我们理解如何考虑人工智能在规划中的作用。
分布式认知的概念使能够评估人工智能和 JMAP 对国防军的适用性。Vaesen 对这一理论总结道:分布式认知(d-cog)背后的基本思想是,认知往往分布在不同的个体和/或认识辅助工具上,如仪器、图表、计算器、计算机等。哈钦斯曾以船舶进港航行为例,对分布式认知进行了著名的阐释。在对美国海军舰船进行广泛研究后,他得出结论:人类和仪器组成的系统共同指挥着船只。这一系统所取得的认知结果超出了任何一个人的思维,也超过了这一过程中每个人单个认知的总和。以这种方式看待人工智能,就会发现它不过是一个已经整合了各种认知人工制品的系统中的另一个非人类元素。人工智能与其他技术(计算机、矩阵、可视化、地图)一样适用于联合监测和评估计划,这些技术已被整合到澳大利亚国防军的规划中。这种将总部理解为分布式认知系统的观点强调了将人工智能与人类智能相结合所产生的潜在效益,而不仅仅是总部数字和生物部分的总和。此外,由于军事总部已经在人类和人工制品之间分配认知,因此人工智能的整合不存在理论上的障碍。
实际上,在 JMAP 中更有利地整合人工智能会是什么样子?规划人员结构的变化是否会像个人电脑出现后文员和打字员队伍的消失一样?是否需要新的工作人员职能来清理和管理数据,或调整和完善算法?美国国防部在 2017 年成立的算法战团队为我们提供了一些思路,即此类团队如何为国防部门的现有结构和职能增值。瑞安在其 2019 年的文章中指出,通过应用人工智能扩展器,可以开发行动模型,根据已知和预测的敌方能力测试和比较各种活动,然后比较不同行动方案实现更高层次结果的能力,从而显著增强并可能加快国防军的规划流程。通过对AI规划流程的比较,同意 Ryan 的观点。澳大利亚战略政策研究所等智囊团也在研究澳大利亚国防军整合人工智能的方法,并得出结论认为,作为一种通用技术,人工智能可以以多种方式应用于澳大利亚国防军。这表明,人工智能与规划的整合可由一项集中的人工智能战略来指导,该战略应考虑到澳大利亚国防军从单个平台层面到战略规划等最高级别功能的需求。
目前,人工智能在规划中的作用存在实际限制。围棋等游戏的规则更为明确,能产生明确的结果。Gibney 警告说,AlphaGo 的规划方法可能很难推广到现实世界的问题中,因为 深度强化学习仍然只适用于某些领域。这归因于实际军事冲突数据的可用性和质量有限,以及在没有简单胜负定义的情况下评估行动方案结果的挑战。人工智能在军事规划任务中的一些实际局限性可以通过合成数据来克服。自动驾驶汽车已经成功地利用真实世界数据与合成数据的结合进行了训练。尽管在实施人工智能增强型规划过程中仍然存在重大的实际障碍,但在将AI应用于实际问题方面却不断取得进展。这些都让我们有理由相信,实际挑战终将被克服。
得出人工智能增强型规划比未增强型 JMAP 更适用于 ADF 的结论不足为奇。然而,通过深入分析一个特定的人工智能规划过程,已经能够超越这种一般性的结论,并探索能够促进或阻碍这种整合的细节。AlphaGo 程序了解其环境并制定和评估行动方案的方式与澳大利亚国防军总部通过 JMAP 完成这些任务的方式类似。分析发现,实施人工智能增强型 JMAP 没有不可逾越的道德或理论障碍。在这一过程中,人类的参与提供了一定程度的监督,这应该能让大多数人工智能军事化的批评者感到满意。参与 JMAP 的军事总部已经采用了非人类辅助认知技术,因此分布式认知技术为从概念上整合人工智能提供了一个很好的方法。在现实冲突中实施人工智能仍面临实际挑战,因为现实环境比围棋更复杂,结构性更差。人工智能的其他各种应用正在克服这些挑战,这无疑将使AI应用于军事问题。
下一篇:扶引术庙堂独享八段锦奉旨健身